What's in an AI citation? Anatomy of how ChatGPT builds an answer from your page
A walkthrough of the five-stage pipeline ChatGPT uses to turn your page into a cited answer—query rewriting, fan-out, retrieval, chunking/reranking, and selective citation—and why most retrieved pages never get cited.

TL;DR
When ChatGPT answers a question, it rewrites the prompt into several sub-queries, retrieves a few hundred candidate pages, chunks and reranks them, and cites only the handful of passages that directly support its claims. A large-scale analysis by AirOps examined 548,534 pages retrieved by ChatGPT across 15,000 prompts and found most are never cited. Getting cited is about surviving each stage, not just ranking.
How does ChatGPT build an answer?
ChatGPT builds an answer through a multi-stage retrieval-augmented generation (RAG) pipeline: it interprets your question, searches the live web, reads selected pages, and writes a synthesized answer with citations attached to specific claims. It does not return ten blue links and leave you to figure out which one has the answer. It reads pages on your behalf, pulls out the relevant information, and synthesizes a direct answer with citations.
The base model is not itself a search engine. ChatGPT is a language model by default, and becomes part of a RAG system when it uses external data sources. When a prompt needs current information, the model triggers a web search, pulls relevant snippets, appends them to your prompt, and generates a grounded response from that combined context.
This matters because your page is never competing for "the answer." It's competing to be one of the few passages that make it into the model's working context, and then one of the even fewer that earn an inline citation.
What are the stages a page passes through?
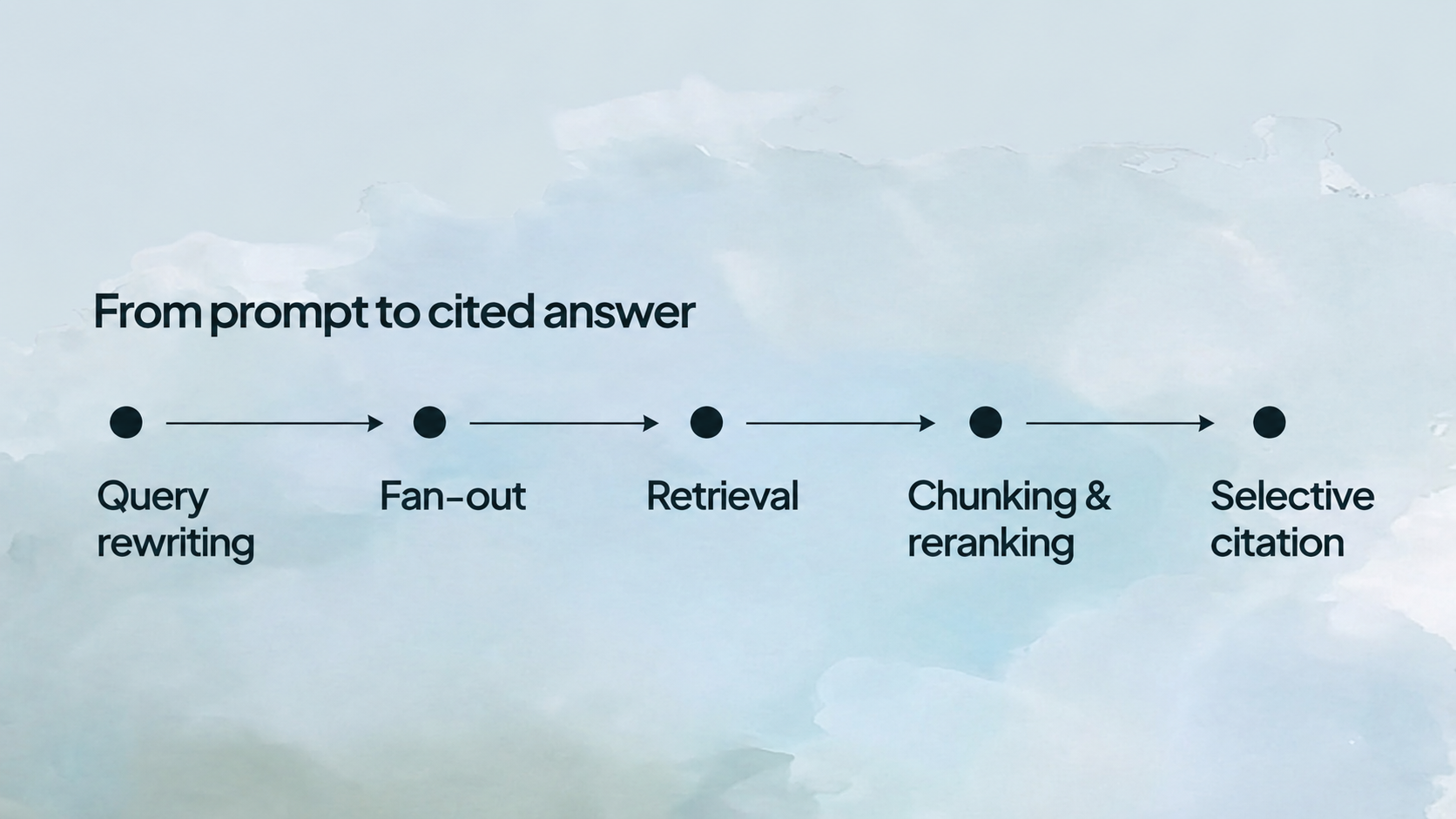
A page passes through roughly five stages between your prompt and a cited answer: query rewriting, fan-out, retrieval, chunking and reranking, and selective citation. A page can clear early stages and still get dropped at the end. Each stage is a separate filter, and most pages fail at least one.
Query rewriting
ChatGPT rarely searches your exact question. It rewrites the prompt into search-engine-friendly phrasing first. Definition queries stay near-verbatim about 51.6% of the time, the highest of any type, while comparison and evaluation queries are far more likely to be reworded or split apart. The wording the model searches is often not the wording the user typed.
Query fan-out
Instead of one search, ChatGPT fires several. Query fan-out deconstructs a single prompt into multiple parallel sub-queries to gather more complete information, with ChatGPT running roughly 2.3 to 2.8 sub-queries per prompt and Google AI Mode firing 9 to 11. A "HubSpot vs Salesforce" prompt can split into separate searches for pricing, features, and reviews.
Fan-out changes the whole optimization problem. The goal is no longer only to rank for the original query, but to cover the follow-up searches ChatGPT generates while building its answer. Ranking for the headline question and nothing else leaves most of the citation surface to competitors.
Retrieval
For each sub-query, the system retrieves a set of candidate pages from the live web. It pulls fresh content from external websites via partner search APIs, unless the information already sits in the model's internal knowledge. One honeypot study found a wrinkle in how this works: when ChatGPT browses following a search, the ChatGPT-User crawler fetches the page content, not OAI-SearchBot as OpenAI's documentation implies. If that crawler can't reach your page, you're out before the analysis even starts.
Chunking and reranking
Retrieved pages are broken into passages, converted to vectors, and ranked by relevance. The system chunks documents into semantically coherent passages, embeds each one as a high-dimensional vector, and runs similarity search to surface the most relevant passages for each sub-query. The unit being judged is the chunk, not the whole page. A great article with one well-targeted section can beat a thin page that happens to rank.
Selective citation
The model then writes its answer and attaches sources only to specific supported claims. Selective citation attaches sources to the claims that depend on them, which is why a page can be read and used without ever appearing as a visible citation.
Why doesn't my page get cited even when ChatGPT reads it?
Most pages ChatGPT retrieves never get cited because retrieval is a wide net and citation is a narrow one. Across the AirOps analysis of 548,534 retrieved pages, the large majority were never cited in the final answer. Being read is the floor, not the goal.

Two findings from that study point to concrete fixes. Pages with strong title-query alignment are cited at more than double the rate of pages with weak alignment, and rewriting a title tag for specificity is often the highest-impact single optimization for a page already being retrieved. Specific, question-shaped titles beat keyword-stuffed ones.
The second is structural. A single pillar page may rank in Google but fail to cover the 8 to 12 sub-questions ChatGPT generates around a topic, while a cluster of supporting pages each answering one sub-question raises the odds of landing in the retrieval set for every fan-out query. Coverage of the fan-out beats depth on one page.
How many sources does ChatGPT actually cite?
ChatGPT cites far fewer sources than other AI engines, which makes each citation slot more competitive. ChatGPT averages 2.6 citations per response, compared to 6.6 for Perplexity and 6.1 for Google Gemini (xFunnel AI, 2025). Fewer slots means the bar for clearing the final stage is higher.
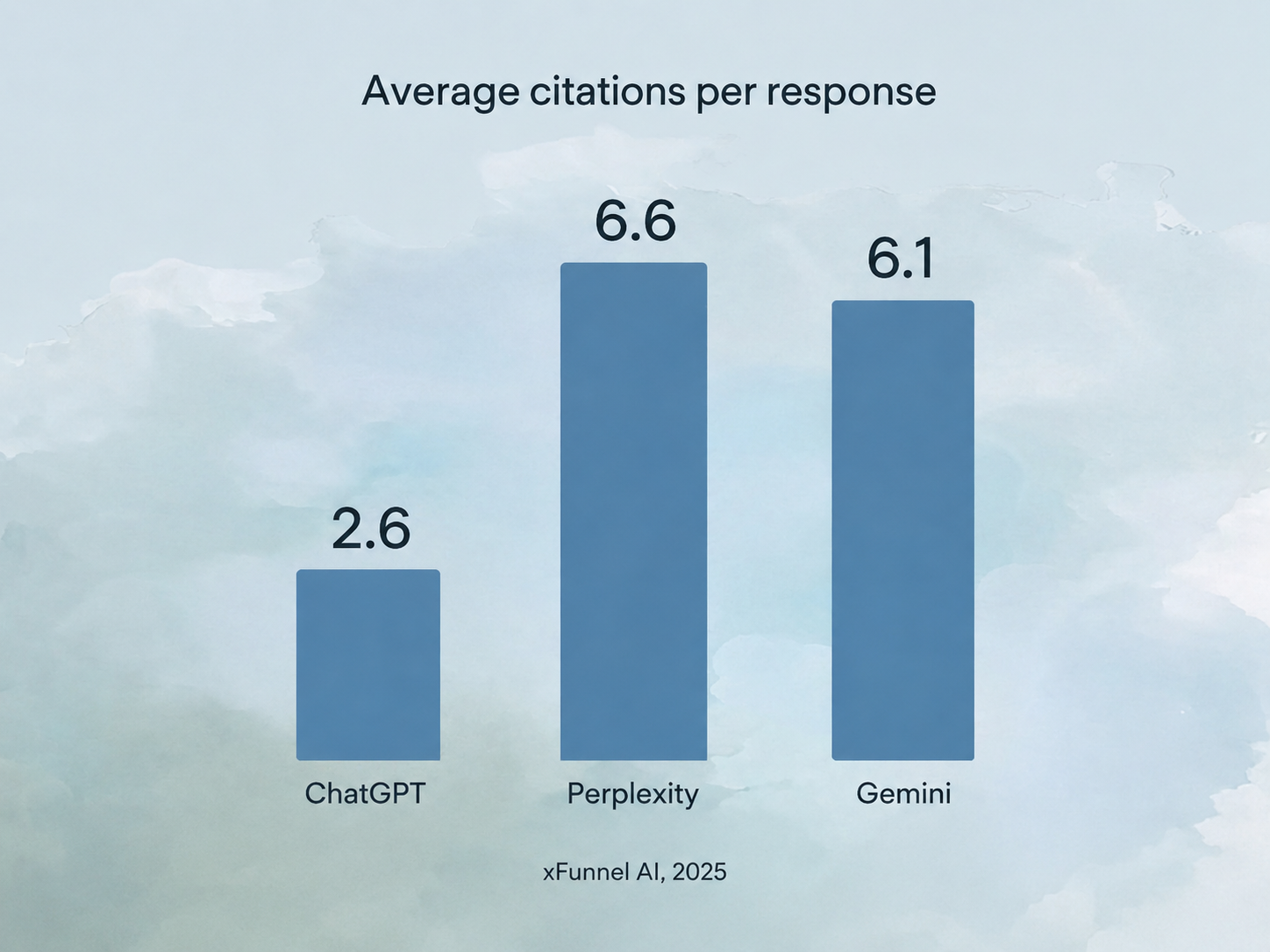
The picture also shifts with model defaults. More than 90% of ChatGPT's weekly users are on the free plan, where the default experience triggers fewer web searches and produces fewer citations, and the number of sites cited per response dropped when OpenAI switched default models. Citation behavior is a moving target tied to product decisions, not a fixed formula.
How ChatGPT citation differs from SEO
Traditional SEO | ChatGPT citation | |
|---|---|---|
Win condition | Rank in the top 10 links | Be cited in the answer text |
Unit judged | The page / domain | The individual chunk |
Query matched | Your target keyword | Several rewritten sub-queries |
Result count | 10 blue links | About 2.6 cited sources |
Recency weight | Moderate | High for time-sensitive prompts |
Ranking #1 for your target keyword no longer guarantees visibility. You might rank #4 for "best project management software" while ChatGPT cites a competitor who ranks well for "Asana vs Trello for remote marketing teams," a sub-query it deemed more relevant.
What does this mean for getting cited?
Getting cited means engineering a page to clear every stage, not just the first one. Make sure the ChatGPT-User crawler can reach the page, write specific question-shaped titles and headers, structure content into self-contained chunks that answer one sub-question each, and build clusters that cover the fan-out rather than one sprawling pillar.
The hard part isn't the tactics. It's seeing the pipeline at all. Most teams have no view into which sub-queries ChatGPT generates for their topics, which of their pages get retrieved, or where a citation slips to a competitor. That's the gap Anagram is built to close. The visibility side tracks which prompts you're actually cited for in ChatGPT and which you're losing, and the on-site agent surfaces the real questions shoppers ask, which exposes the fan-out gaps worth writing for. The point is to make the black box legible: see the searches you're invisible across, then close them on purpose. Plenty of tools, including Profound and Scrunch, track AI citations well; what's worth pushing on is connecting that tracking to the content gaps it reveals.
Frequently asked questions
Does ChatGPT search the web for every question?
No. The model only triggers a web search when it judges that current or external information is needed. For prompts it can answer from training data, it relies on its internal knowledge with a fixed cutoff; for recent or specific information, it sends a query to its search system and grounds the answer in what it retrieves.
Is being retrieved the same as being cited?
No. Retrieval means ChatGPT pulled and read your page as a candidate. Citation means a specific claim in the answer was attributed to it. Most retrieved pages are never cited, so retrieval is necessary but not sufficient.
Why does ChatGPT cite a competitor who ranks below me?
Because citation is decided per sub-query and per chunk, not by overall domain ranking. A competitor who ranks well for a specific sub-query ChatGPT deemed relevant can be cited even when you rank higher for the broad head term.
Does schema markup get my page cited?
It can help machine-readability, but it's not the deciding factor. Crawler access, title-query alignment, chunk structure, and topical coverage of the fan-out do more of the work, based on the retrieval studies above.
Sources
Rankly, "How ChatGPT Search Works: The 7-Stage Pipeline Behind Every Answer" (2026)
upGrad, "Is ChatGPT a RAG? Understanding How AI Retrieves Information" (2026)
AirOps, "The Influence of Retrieval, Fan-out, and Google SERPs on ChatGPT Citations" (2026)
ALM Corp / AirOps, "Why 85% of Pages ChatGPT Retrieves Are Never Cited" (2026)
Search Engine Land, "Inside ChatGPT Search: how web.run and fan-out queries shape AI visibility" (2026)
omnius, "Understanding Query Fan-Out for Better AI Search Visibility" (2025)
upGrowth, "Query Fan-Out Explained: AI Mode + ChatGPT" (2026)
Visiblie, "How AI Platforms Choose What to Cite: RAG Explained" / xFunnel AI (2026)