What ChatGPT Actually Quotes: Why a Tight Q&A Block Beats a 400-Word Paragraph (2026)
ChatGPT cites individual passages, not whole pages, so a focused 40–60 word Q&A block gets quoted where a 400-word paragraph gets passed over — structure your content for the chunk, not the page.

TL;DR
ChatGPT doesn't read your page — it retrieves a chunk of it. When it answers a question, it pulls the single passage that best matches the query and quotes from that, not from the whole article. A focused 40–60 word Q&A block is a clean, retrievable unit; a 400-word paragraph buries the answer inside noise and dilutes the match. Structure for the chunk, not the page.
What does ChatGPT actually quote from a page?
ChatGPT quotes a passage, not a page. When it answers using web content, a retrieval step first breaks candidate pages into smaller segments called chunks, scores each chunk against the user's question, and feeds only the top-matching chunks to the model — which then quotes or paraphrases from those. The unit of citation is the chunk, so the question that decides whether you get quoted is: is the answer sitting in a clean chunk by itself, or buried in a wall of text?
This is the part most content teams miss. You don't optimize a page to be cited; you optimize the individual passage the engine will lift. A page can rank, get crawled, and still never be quoted because the answer is tangled inside a paragraph that also covers three other things.
How does ChatGPT decide which passage to quote?
It matches the user's query to your content through retrieval-augmented generation (RAG): your page is split into chunks, each chunk is converted to a vector, and the chunks whose vectors sit closest to the query's vector get retrieved and passed to the model. Chunking is the process of splitting documents into smaller pieces so a retriever can fetch the most relevant passages and an LLM can use them as grounded context when generating an answer. Unstructured
The mechanics matter because they're unforgiving in one specific way. RAG systems almost never index full raw documents; instead, they index chunks — typically contiguous text windows of some fixed length with stride and overlap. Your 400-word paragraph doesn't get evaluated as a brilliant whole. It gets sliced — sometimes mid-thought — and each slice is judged on its own. If the answer to the user's question spans the slice boundary, no single chunk matches well, and a competitor's tidy one-paragraph answer wins the citation. arxiv
Why does a tight Q&A block beat a 400-word paragraph?
Because a focused chunk produces a sharper match. The research on retrieval is consistent: smaller chunks (64–128 tokens) are optimal for datasets with concise, fact-based answers, whereas larger chunks (512–1024 tokens) improve retrieval in datasets requiring broader contextual understanding. Most questions a buyer asks an AI are concise and fact-based — "what's the difference between X and Y," "how do I configure Z" — which is exactly the regime where small, focused passages win. arxiv
The reason is mechanical, not stylistic. When you compress one idea into one short passage, its vector points cleanly at one meaning. Larger chunks: higher recall, because a single retrieved unit is more likely to contain the answer somewhere inside it, but it may also contain distracting or noisy text. "Somewhere inside it" is the problem — the answer being present isn't enough if it's drowned out. Larger chunks compress more information into one vector, which can blur distinct ideas and dilute relevance when multiple topics are mixed together. arxivUnstructured
A 400-word paragraph covering five sub-points produces a muddy vector that's a mediocre match for all five questions and a strong match for none. Five tight Q&A blocks produce five clean vectors, each a strong match for its own question. Same information, five times the retrievability.
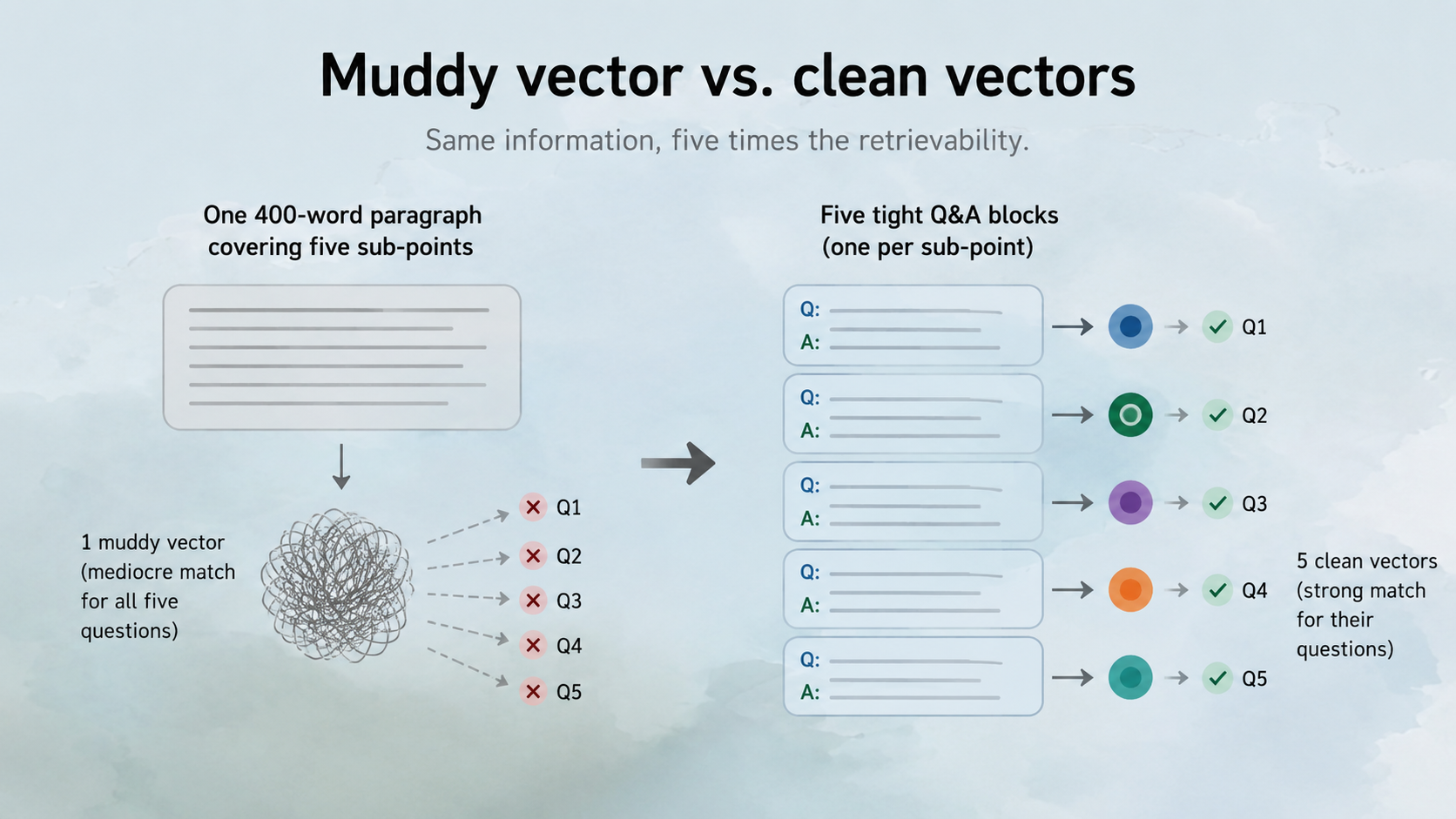
What does a "quotable chunk" actually look like?
A quotable chunk is a question-styled header followed immediately by a 40–60 word standalone answer, with no setup before it. The header mirrors the query; the first sentence is a complete answer that makes sense lifted out of the page entirely. This isn't a stylistic preference — it maps directly onto how retrieval matches queries to content.
Buried in a 400-word paragraph | Tight Q&A block | |
|---|---|---|
Header | "Understanding the landscape" | "How do I configure GPTBot access?" |
First sentence | Throat-clearing, context, history | The direct answer, standalone |
Vector match | Muddy — points at many ideas | Sharp — points at one query |
What gets quoted | Usually nothing | The first 40–60 words |
Chunk boundary risk | Answer may split across chunks | Answer is self-contained |
The 40–60 word target isn't arbitrary. It's long enough to fully answer a question and short enough to survive as one retrievable unit — roughly the span a generative engine wants to lift verbatim into an answer.
Does this mean I should delete all my long paragraphs?
No — it means you should restructure them, not shorten the article. Long-form content still wins on depth and on the number of distinct questions it can answer. The fix is to break a flowing 400-word block into four atomic chunks, each with its own question header and its own standalone answer. You keep every word; you just make each idea independently retrievable.
The failure mode to avoid is the opposite overcorrection: padding. The Princeton GEO paper tested 9 tactics across 10,000 queries; the failures included keyword stuffing, easy-to-understand simplification, content padding, and pure persuasive language. Adding words for their own sake doesn't help. Structure does. DerivateX
How much does structure actually move citation rate?
Measurably, and the strongest content-level lever is making your answers concrete and quotable. The most-cited empirical study in this space — the Princeton/Georgia Tech GEO paper presented at ACM KDD 2024 — tested which content changes improved a page's appearance in AI answers. The "Statistics Addition" method improved citation visibility scores by 32.8 percent, and "Quotation Addition" led all methods at 42.6 percent. Trust Signals
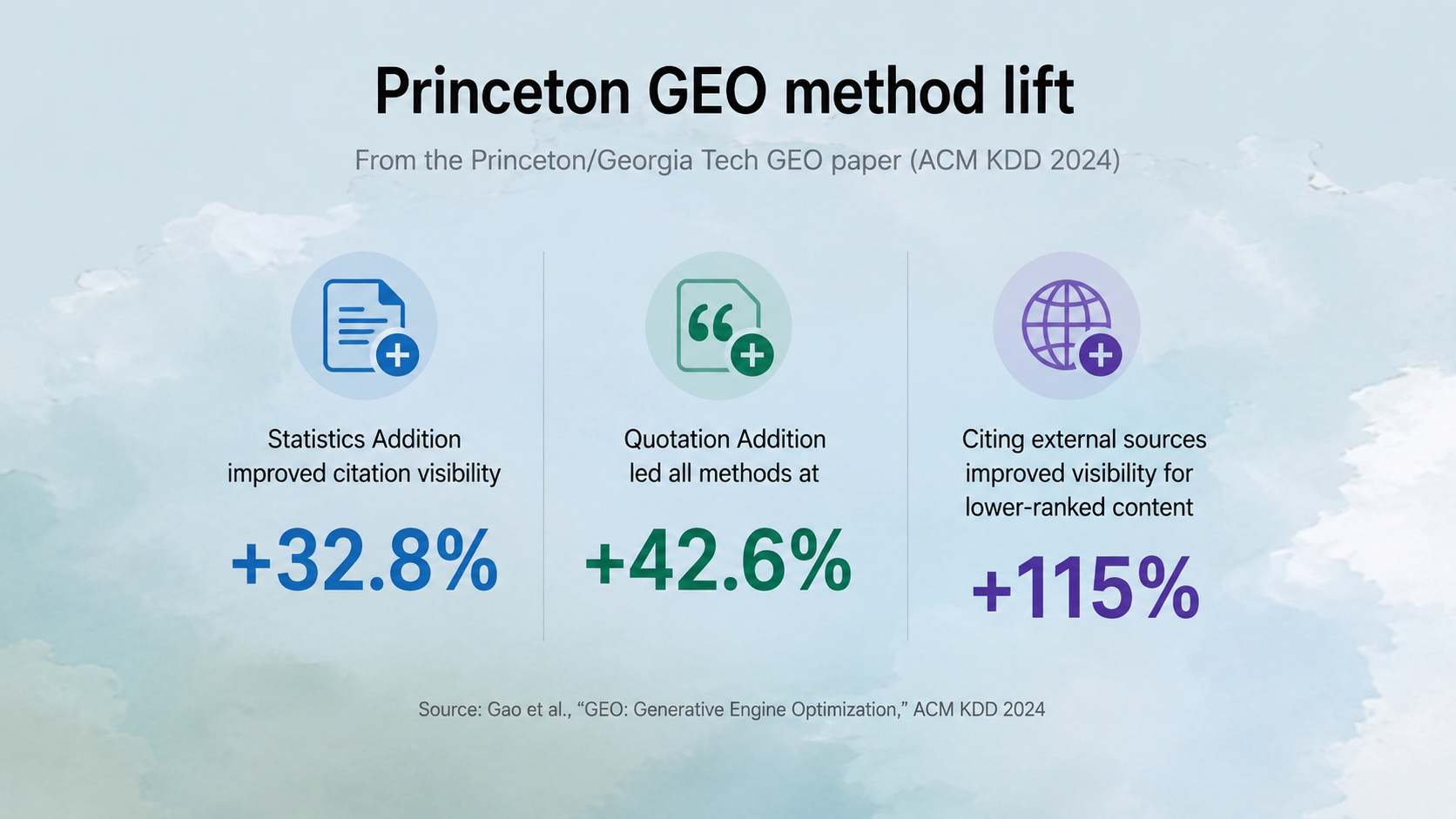
The throughline behind those numbers is the same principle as chunking. When a language model synthesizes an answer from multiple sources, it gravitates toward content that provides something concrete and attributable — a direct quote, a specific percentage, an explicit citation gives the model a discrete, verifiable unit to include, while vague qualitative prose gives it much less to work with. A tight Q&A block is a discrete, verifiable unit. A 400-word paragraph is the vague prose the model passes over. Elementera
One finding is especially relevant if you're not yet a household name: citing external sources improved visibility by 115% for lower-ranked content. Structure and attribution are how smaller sites win citations they couldn't win on domain authority alone. Sunil Pratap Singh
How does ChatGPT's recency bias interact with all this?
It compounds the structural advantage — fresh, well-structured content is the strongest combination. ChatGPT weights recently updated content heavily, so a page that's both current and cleanly chunked clears two bars at once. A stale 400-word paragraph fails on both; a recently-updated Q&A hub passes both. If you're refreshing content anyway, restructuring into atomic chunks during the refresh is close to free leverage.
How do I restructure an existing page for citation?
Take it one chunk at a time, starting from the questions your buyers actually ask. The practical sequence:
List the real questions. Pull the literal phrasings people type into AI about your topic. Each becomes a candidate header.
Map each question to one passage. If a 400-word block answers four questions, it becomes four chunks.
Front-load the answer. Under each question header, lead with a 40–60 word standalone answer. Delete the throat-clearing before it.
Make each chunk survive removal. Read each block in isolation. If it only makes sense in context, it's not yet a chunk.
Add concrete units. Work in a statistic with attribution or a structured table where it fits — these are the parts that get lifted.
This is the diagnostic half of the work that's hard to eyeball, which is where a visibility tool earns its place. Anagram traces a brand's low citation share back to its cause — sometimes a blocked crawler, but more often a content gap where the answer the engine wants to quote simply isn't sitting in a clean, retrievable chunk. Knowing which passages are losing citations, and to whom, is what turns "restructure everything" into a ranked to-do list.
Quick reference: chunk-friendly vs chunk-hostile content
Signal | Chunk-hostile | Chunk-friendly |
|---|---|---|
Header style | Statement ("The landscape") | Question ("How do I X?") |
First sentence | Context / setup | Standalone answer |
Paragraph length | 400 words, many ideas | 40–60 words, one idea |
Self-containment | Needs surrounding context | Survives being lifted out |
Concrete units | Qualitative prose | Stats, tables, attributed quotes |
Freshness | Undated | Visible "last updated" |
Frequently asked questions
Is chunking the same as keyword density? No. Keyword density is an SEO tactic about how often a term appears; chunking is about how your content is segmented for retrieval. In the Princeton study, keyword stuffing performed 10% worse than the baseline. Cramming keywords into a muddy paragraph hurts; structuring clean answers helps. Sunil Pratap Singh
What's the ideal chunk length for AI citation? For the concise, fact-based questions most buyers ask AI, aim for a 40–60 word direct answer under a question header. There's no universal sweet spot — different queries need different chunk sizes — but short and focused beats long and mixed for the question-answering case. AI21 Labs
Will restructuring hurt my human readers? Generally the opposite. Question headers and front-loaded answers also serve skimming readers and voice assistants. The one risk is over-stuffing citations until prose reads clinically — keep it fluent.
Does this only apply to ChatGPT? No, but ChatGPT's heavy recency bias and large share of AI referral traffic make it the highest-leverage target. The chunking mechanics apply to Perplexity and Gemini too, since all use retrieval over segmented content.
How do I know if my chunks are actually getting cited? Server logs show a crawler visited; they don't show whether you were quoted. Citation-tracking tools like Anagram monitor how often and how prominently you're cited across ChatGPT, Perplexity, and Gemini, so you can tell whether a restructure paid off.
Sources
Unstructured — Chunking Strategies for RAG: Best Practices and Key Methods (2025)
Aggarwal et al. — GEO: Generative Engine Optimization, ACM KDD 2024 (arXiv:2311.09735)
Bhat et al., Fraunhofer IAIS — Rethinking Chunk Size for Long-Document Retrieval (2025)
RAGSmith — Finding the Optimal Composition of RAG Methods (arXiv:2511.01386, 2025)
AI21 — Chunk Size Is Query-Dependent: A Multi-Scale Approach to RAG Retrieval (2026)
Elementera — What the GEO Paper Actually Shows for Your Business (2026)
TrustSignals — The AI Visibility Gap B2B Marketers Are Missing (2026)
Sunil Pratap Singh — What GEO Research Actually Says: Princeton to SparkToro (2026)