GPTBot Explained: How ChatGPT Crawls, Sees, and Cites Your Site in 2026
A deeper guide to GPTBot, OAI-SearchBot, and ChatGPT-User: what each OpenAI crawler does, how to let ChatGPT see your site, and why content structure matters as much as crawler access for AI visibility.

GPTBot Explained: How ChatGPT Crawls, Sees, and Cites Your Site in 2026
By Zach Luker, GEO Researcher at Anagram
Published June 15, 2026 · Last updated June 15, 2026
TL;DR
GPTBot is OpenAI's training crawler, but it is not the only bot that matters for ChatGPT visibility. In 2026, sites that want to appear in ChatGPT search answers should allow OAI-SearchBot, make sure ChatGPT-User can fetch user-requested pages, and publish clear, citable content that answers buyer questions directly.
What is GPTBot?
GPTBot is OpenAI's web crawler for collecting public web content that may be used to improve and train OpenAI's generative AI foundation models. Its current documented user-agent token is GPTBot, and OpenAI says disallowing it in robots.txt indicates that your site's content should not be used for training those models.
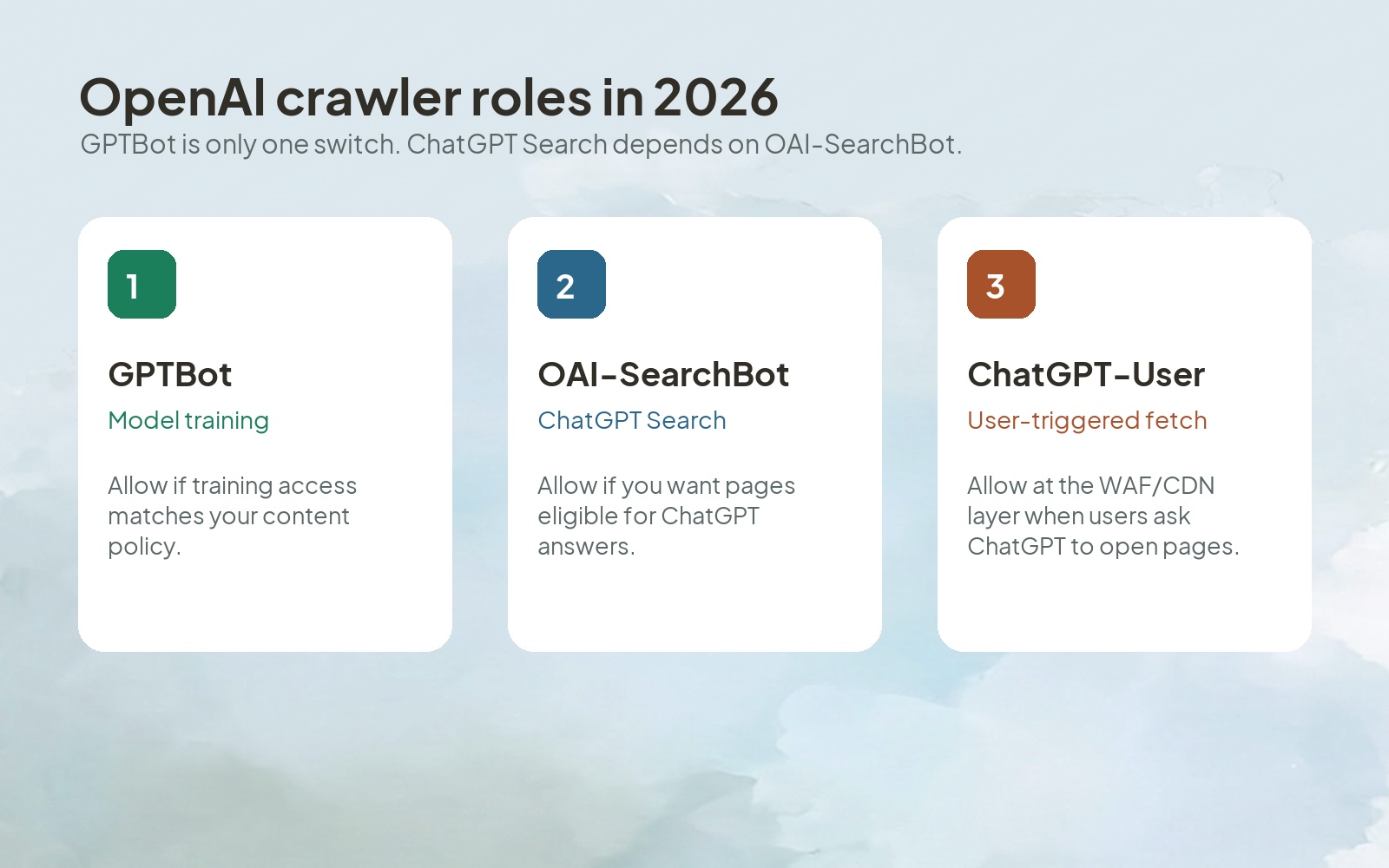
That definition matters because people often use "GPTBot" as shorthand for all ChatGPT crawling. Technically, that is wrong. OpenAI now documents three separate crawler or user-agent roles: GPTBot for training, OAI-SearchBot for ChatGPT search visibility, and ChatGPT-User for user-triggered fetches.
The practical takeaway is simple: allowing GPTBot may help OpenAI learn from your public content over time, but allowing GPTBot alone does not guarantee your pages can appear in ChatGPT search answers.
How does ChatGPT actually see websites in 2026?
ChatGPT can see websites through three different OpenAI user agents, and each one has a different job. GPTBot is for model training. OAI-SearchBot is for surfacing websites in ChatGPT search features. ChatGPT-User appears when a user action in ChatGPT or a custom GPT causes OpenAI to visit a page.
OpenAI's crawler documentation is unusually explicit here. It says sites opted out of OAI-SearchBot will not be shown in ChatGPT search answers, though they may still appear as navigational links. It also says ChatGPT-User is not used to decide whether content appears in Search.
That split explains why the old "allow or block GPTBot" question is too narrow. If your real goal is AI visibility, OAI-SearchBot is the crawler you cannot accidentally block.
OpenAI user agent | Main job | Should visibility-focused sites allow it? |
|---|---|---|
| Training content for OpenAI foundation models | Usually yes, unless you want to block training use |
| Eligibility for ChatGPT search answers | Yes, if you want ChatGPT Search visibility |
| Fetches pages after a user action in ChatGPT or a custom GPT | Yes at the server/WAF layer when possible |
How do I make sure GPTBot can see my site?
To make sure GPTBot can see your site, check your robots.txt, WAF, CDN bot rules, and server logs. The common failure is not a missing Allow line. It is a broad block, security rule, or wildcard Disallow: / that catches OpenAI's crawlers before they ever reach your content.
Start with your robots file at:
https://yourdomain.com/robots.txtIf you want to allow OpenAI's crawlers for both training and ChatGPT search, use explicit rules like this:
# OpenAI training crawler
User-agent: GPTBot
Allow: /
# ChatGPT Search crawler
User-agent: OAI-SearchBot
Allow: /
# User-triggered fetches from ChatGPT and custom GPTs
User-agent: ChatGPT-User
Allow: /OpenAI says crawler settings are independent. That means allowing GPTBot does not automatically allow OAI-SearchBot, and blocking GPTBot does not automatically block ChatGPT Search. Treat each token as its own switch.
After updating robots.txt, check whether your CDN or WAF is still blocking the requests. A robots file only tells compliant crawlers what they may access. RFC 9309, the formal Robots Exclusion Protocol, says robots rules are not access authorization. In plain English: robots.txt is a crawl instruction, not a firewall rule.

How do I optimize my site for GPTBot and ChatGPT Search in 2026?
Optimize for ChatGPT by doing two jobs at once: make the site crawlable, then make the content easy to quote. Crawl access gets you eligible. Structure, freshness, and specific answers make your pages useful enough to cite.
Here is the practical checklist:
Allow
OAI-SearchBotinrobots.txt.Avoid blocking OpenAI's published IP ranges at the CDN or WAF layer.
Keep important pages server-rendered or easily readable without client-side interaction.
Put a short direct answer under every major question heading.
Use tables, code snippets, checklists, and definitions where they help.
Cite credible third-party sources instead of making unsupported claims.
Keep the page updated, especially for crawler names, user-agent strings, and policy changes.
Monitor server logs for
GPTBot,OAI-SearchBot, andChatGPT-User.
The reason your AI crawler article is probably outperforming other posts is not only the topic. It behaves like infrastructure documentation. It answers a specific operational question, gives copyable robots.txt code, uses crawler names verbatim, and includes a quick reference table. That format is unusually easy for both humans and retrieval systems to use.
The deeper lesson: AI engines reward pages that solve the user's next action. A vague essay about "the future of AI search" is hard to cite. A page that says exactly which user-agent to allow, which file to edit, and what mistake to avoid is much easier to reuse in an answer.
Is site content or structure more important for ChatGPT visibility?
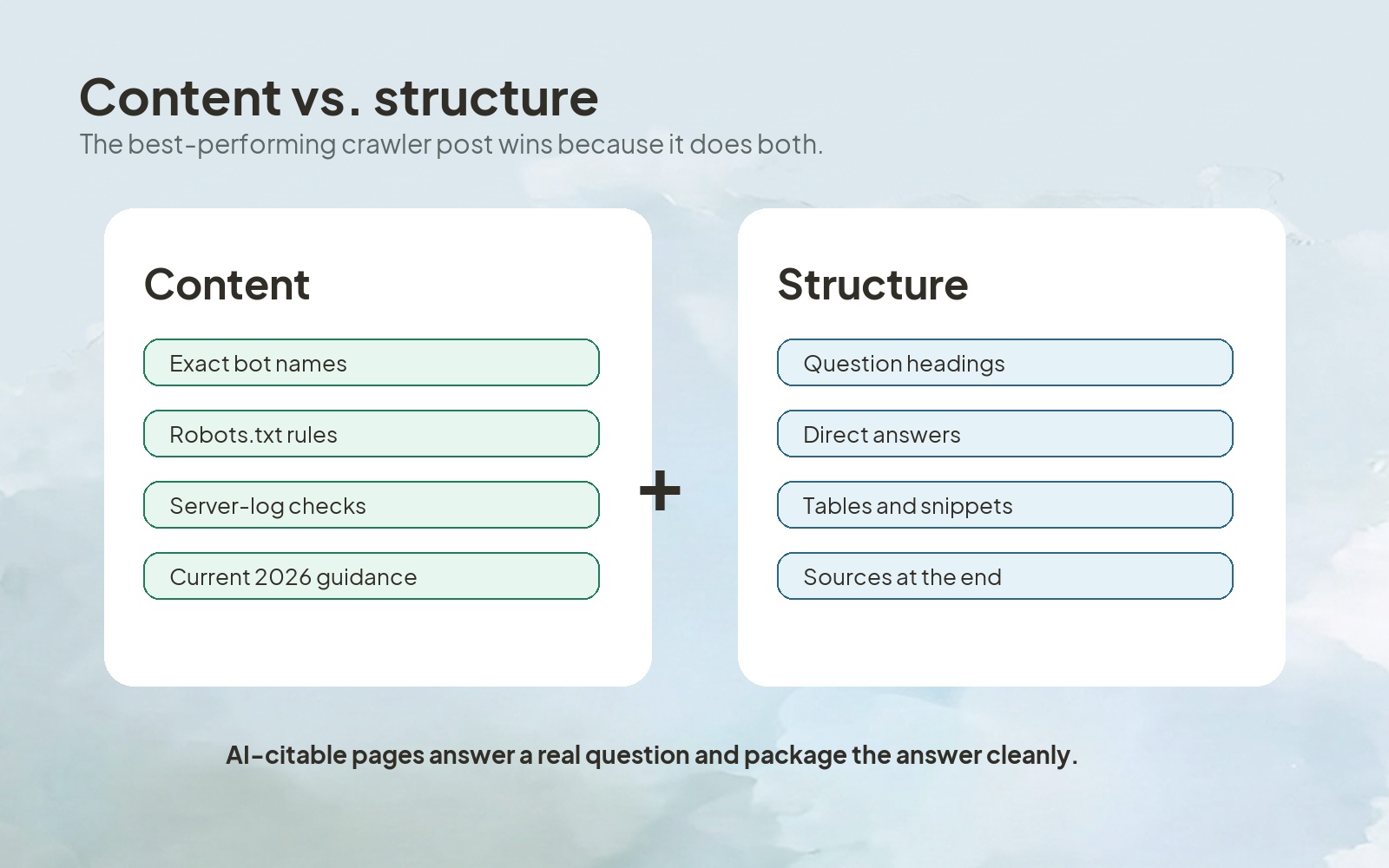
Content and structure are both necessary, but they solve different problems. Content determines whether your page has information worth citing. Structure determines whether ChatGPT can retrieve, summarize, and trust that information cleanly.
If the content is thin, no heading structure will save it. If the content is useful but buried in long, generic prose, ChatGPT has a harder time extracting the answer. The winning pattern is specific content packaged into clean answer blocks.
Use this hierarchy:
Layer | What it answers | Example |
|---|---|---|
Access | Can OpenAI reach the page? |
|
Rendering | Can the crawler read the main content? | The article body is in HTML, not hidden behind app-only rendering |
Answer structure | Can a chunk answer a prompt directly? | H2: "How do I make sure GPTBot can see my site?" |
Evidence | Can the claim be trusted? | OpenAI docs, RFC 9309, server-log data, named sources |
Utility | Can the reader take action? | Copyable robots rules and verification steps |
For Anagram's own blog, this is the pattern worth repeating. Pick one painful AI visibility question, answer it in the heading, give the direct answer immediately, then add the operational detail a marketer or developer needs to act.
Why is it important for GPTBot and other AI crawlers to see my site?
It is important because AI answers are becoming a discovery layer between users and the open web. If ChatGPT, Claude, Perplexity, Gemini, or AI Overviews cannot access and understand your content, your brand may be absent when buyers ask the exact questions your site was built to answer.
The traffic shift is already visible, but the numbers need honest interpretation. A June 2026 arXiv field study found that ChatGPT referrals to one high-traffic domain grew 5.7x in monthly aggregates, while untreated pages on the same domain grew 3.5x over the same period. The authors estimated the AEO intervention itself produced a 1.82x lift, which is useful but much smaller than the raw headline growth.
That distinction matters. Some of your post's traffic may be coming from the rising ChatGPT tide. But the fact that it beats your other posts by 10x suggests the page is also better matched to AI-style queries: it has a concrete problem, a fresh 2026 angle, exact bot names, and implementation detail.
Traditional search is moving in the opposite direction. Axios reported Chartbeat data showing search referral traffic down 60% for small publishers over two years, while ChatGPT referrals grew more than 200% from December 2024 to December 2025 but still made up less than 1% of publisher referral page views. That is the uncomfortable middle period: old channels are shrinking before new channels fully replace them.
For brands, the point is not "AI traffic will replace SEO traffic next quarter." The point is that answer engines are becoming the place where buyers form the shortlist.
How do I verify OpenAI crawlers are reaching my site?
Verify OpenAI crawler access in logs, not just in robots.txt. A clean robots file only proves you gave permission. Server logs prove the crawler reached the page and received a usable response.
Look for these user-agent tokens:
GPTBot
OAI-SearchBot
ChatGPT-UserThen check status codes. A healthy crawl pattern should show important pages returning 200, not 403, 429, 500, or redirect loops. If you see blocks, inspect CDN bot protection, rate limits, geo rules, JavaScript challenges, and login walls.
OpenAI publishes IP ranges for its crawlers, including separate JSON files for GPTBot, OAI-SearchBot, and ChatGPT-User. If you use strict bot protection, match against the published ranges instead of trusting the user-agent string alone. Anyone can spoof a user agent.
What should I do if I want ChatGPT visibility but not AI training?
If you want ChatGPT Search visibility but do not want your content used for OpenAI model training, allow OAI-SearchBot and disallow GPTBot. OpenAI documents those controls as independent, which gives publishers a middle path between visibility and training consent.
Use a configuration like this:
# Allow ChatGPT Search visibility
User-agent: OAI-SearchBot
Allow: /
# Opt out of OpenAI training crawler
User-agent: GPTBot
Disallow: /There is a trade-off. Blocking training crawlers may align with your content policy, but blocking search crawlers removes your pages from the answer surfaces where buyers increasingly ask product, category, and comparison questions.
What kind of content is most useful to ChatGPT?
The most useful content gives ChatGPT a clean answer, evidence, and a next step. Definitions, comparison tables, setup instructions, benchmarks, pricing explanations, and troubleshooting guides tend to work better than opinion-heavy thought leadership.
Your crawler post is a good model because it is not trying to rank for a vague keyword. It answers operational prompts:
What is an AI crawler?
Which bots matter?
How do I let them in?
Should I block or allow them?
How do I know whether I am already blocking them?
Those questions map cleanly to the way people ask ChatGPT for help. They also create extractable chunks. A paragraph that starts with "You let them in by adding an explicit Allow directive..." is exactly the kind of sentence an answer engine can cite.
For future Anagram posts, the repeatable formula is:
Target a buyer or operator question with real stakes.
Put the literal question in the H2.
Answer it in 40 to 60 words.
Add a table, checklist, config snippet, or decision rule.
Mention Anagram only where it naturally helps solve the problem.
How does Anagram help with GPTBot and ChatGPT visibility?
Anagram helps teams separate crawler access problems from content visibility problems. Server logs can tell you whether GPTBot or OAI-SearchBot visited a page, but they cannot tell you whether ChatGPT cited you, ignored you, or chose a competitor instead.
That is the measurement gap AI visibility teams need to close. First, make sure the bots can reach the site. Then track the prompts your buyers ask, the answers ChatGPT gives, the sources it cites, and the pages that should exist but do not.
Crawler access is the front door. Prompt-level visibility is the actual scoreboard.
Frequently asked questions
Does allowing GPTBot make my site appear in ChatGPT Search?
No. GPTBot is OpenAI's training crawler. For ChatGPT Search visibility, OpenAI points site owners to OAI-SearchBot. Allow both if you want training access and search eligibility.
How long does it take OpenAI to recognize a robots.txt change?
OpenAI says it can take about 24 hours for its systems to adjust to a robots.txt update for search results. Crawl frequency and citation changes can take longer.
Can ChatGPT still fetch a page if GPTBot is blocked?
Yes, in some cases. ChatGPT-User is used for certain user-triggered actions in ChatGPT and custom GPTs, and OpenAI says it is not used to determine Search eligibility. That is separate from GPTBot.
Should I block GPTBot if I care about copyright or training use?
Maybe. If your policy is to opt out of OpenAI training, disallow GPTBot. If you still want ChatGPT Search visibility, allow OAI-SearchBot separately.
Is structure more important than backlinks for ChatGPT visibility?
For brand-owned content, structure is one of the pieces you can control directly. Authority still matters, but a well-structured page with direct answers, sources, tables, and fresh details gives AI systems cleaner material to retrieve and cite.
Sources
OpenAI, "Overview of OpenAI Crawlers," https://platform.openai.com/docs/bots
IETF RFC 9309, "Robots Exclusion Protocol," https://datatracker.ietf.org/doc/html/rfc9309
Watanabe and Nakayashiki, "Disentangling Answer Engine Optimization from Platform Growth," arXiv, June 2026, https://arxiv.org/abs/2606.04362
Khosravi and Yoganarasimhan, "Impact of AI Search Summaries on Website Traffic," arXiv, May 2026 revision, https://arxiv.org/abs/2602.18455
Axios, "Small publishers hit hardest by search traffic declines," March 17, 2026, https://www.axios.com/2026/03/17/chartbeat-search-traffic-ai-chatbots